ナラベルとは
ナラベルは,テーマを自由に設定して,書籍とWebページをまとめて公開できるWebサービスです。
想定している利用者と利用方法は,以下のとおりです。
【利用者】
- 公共図書館,学校図書館,専門図書館,美術館,博物館
- 図書館員,司書,図書館を基盤に活動しているグループ(図書館友の会など)
- 展覧会や催事,研究会を主宰する方や組織
- 授業や講義,講座などを開催している方や組織
- 研究活動や調査活動などを行いその成果を公表している個人や組織
- その他,書籍やWebページをリスティングして公開・配布している個人や組織
【利用方法】
- 図書館や学校で行う書籍に関わる展示をWebで公開する。
- 図書館や学校で作成しているいろいろな書籍リストをWebで簡単に公開する。
- 展示会や催事の実施に合わせて,補足情報として書籍やWebの情報をまとめて公開する。
- いろいろな講座や授業などで必要となる参考資料のリストを作って公開する。
- 個人で調べたことを公開・広報する際に,参考資料として本やWebページをまとめて公開する。
利用までの手順は非常にシンプルで,
- ユーザー登録をする
- テーマを設定する
- 本やWebを登録する
- 公開する
の4ステップだけです。
*2023年10月25日にユーザー登録なしで本棚を作成できるゲスト機能が追加されました。
ユーザー登録するには、X(旧Twitter)もしくはGoogleのアカウントが利用できます。もしこれらのアカウントをお持ちでない場合には、ナラベルWebサービスの独自ユーザー登録をご利用いただけます。
ユーザーは専用ページを持ち,まとめたいテーマを設定することができます。専用ページのスタイルやタイトルは,ユーザー自身で変更できます。また,作成したテーマを簡単にツイートすることもできます。
本の情報を登録する際に必要なのは,ISBNだけです。タイトルや著者は,openBDをメインに,いくつかの書誌データベースから流用します。また,書誌データベースに書影情報がある場合には,自動的に書影画像が表示されます。
Webページの場合は,URLだけあればOKです。指定したURLの画面スクリーンショットが,本の書影と同じく自動で表示されます。
設定したテーマには,1枚の画像をアップロードして表示することができます。例えば,資料展示であれば,展示イメージの写真を,展覧会であれば,展覧会のパンフレットイメージを,テーマと共に表示できます。イメージ画像をアップロードしなかった場合には,テーマに登録した書籍の書影やWebページのスクリーンショットが自動的に表示されます。
登録したテーマごとに,CSV形式でデータをダウンロードすることも可能です。これまで,書籍リストを手作業で作成していたのであれば,ナラベルにISBNを使って資料を一括登録するだけで,簡単に書籍リストを作ることができます。
ナラベルではテーマごと,情報ごとに公開と非公開を決められます。また日程を事前に決めて,予約公開することも可能です。プライベートな利用として,全く公開しないこともできます。さらに,展示会や催事と連動する場合には,展覧会や催事の開催期間を表示することも可能です。
ナラベルは,いろいろなWebサービスとの連携もできます。新着情報はRSSで配信します。ご自分のWebサイトやホームページへ,<iframe>タグを使って,組み込むこともできます。OGP(Open Graph Protocol)にも対応しているので,SNSでのナラベルへのリンクもSNSでのリンクデザインが適用されます。
ナラベルは,簡単な操作とシンプルな画面デザインで,いままでちょっと面倒だったことを,気軽にできるようにします。あなたの手元に眠っている情報が,わずかな手間で多くの人たちの役に立つかもしれません。
ぜひ,ナラベルをご活用ください。
openBD API(バージョン1)の提供終了に伴う書誌ユーティリティの取り扱いについて
openBD API(バージョン1)の提供が終了し、その後の対応として、以下のようなアナウンスがされました。
openbd.jp
これに伴い、ナラベルWebサービスでは、これまで利用していた書誌ユーティリティに加え,GoogleBooksを追加することとしました。これにより、書籍情報を登録する場合に利用する書誌ユーティリティは,
1)openBD
2)GoogleBooks
3)楽天Books
4)NDL
となります。openBDから配信さてれいたデータの内容・カバー範囲が変更となりましたが,ナラベルWebサービスではこれまでどおり,openBDも利用します。GoogleBooksの利用により,書影のカバー率はある程度維持できますが,目次およびあらすじ情報については,取得できる量は低下します。
これに伴い、複数の書誌ユーティリティに情報が存在する場合の優先順位は、目次・あらすじ情報優先から、書影データの有無を優先することにしました。なお,GoogleBooksの書誌を利用した場合には,GoogleBooksへのリンク情報が表示されます。
すでに登録されたopenBDの書誌情報,特に書影情報で提供されなくなったものについては,主にGoogleBooksのデータを利用して,随時差し替え処理を行い,書影の表示率を回復させる予定です。加えて,NDLの書誌を利用しているもののうち,ISBNを持ってるデータについては,GoogleBooksを利用して,書影が表示可能となる場合には,随時差し替えていく予定です。
今後とも、ナラベルWebサービスを快適にご利用いただけるように、鋭意改善を進めていく予定です。
openBD API(バージョン1)の提供終了に関するナラベルWebサービスの対応について
2023年7月25日にopenBD API(バージョン1)の提供終了がアナウンスされました。
openbd.jp
ナラベルWebサービスの書誌情報は、openBD、楽天Books、NDLから取得していますが、カバー率では、openBDが7割程度でした。このため、openBD APIの提供終了は、ナラベルWebサービスに大きな影響を与えることは確実です。
そこで、ナラベルWebサービスは、この影響を最小限にするために、以下の対策を実施する予定です。
この2つの対策によって、これまでの書誌情報のカバー率を維持できる
かどうかは分かりませんが、可能なかぎりより多くの書誌情報を
取得できるように機能追加を実施します。
なお、現在openBDから提供されている書誌情報については、openBDの今後の動向が判明したのち、適切に処理する予定です。
最後に、これまでopenBDを運用していただいた皆様に、感謝申し上げます。
皆様の活動により、書誌情報の流通が劇的に自由になり、多くのWebサービスが誕生しました。ナラベルWebサービスもその一つです。
現状、openBDが厳しい状況にあることは推察されますが、もし、私たちのようなopenBD利用者にできることがあれば、
可能なかぎり支援していきたいと考えています。
Twitter連携ログインのOAuth2.0への対応
これまでのTwitterAPI有料化の騒動について,多数の制限が設定されたことも問題ですが,開発者の視点では,「いつ何が起こるかが分からない」と常に心配しなければいけないことが,もっとも厳しいことではないかと思います。突然,サービスが停止する,APIが使えなくなる,有料になる,心配ごとは絶えないですが,数多くのユーザーとツールとして影響力を維持している限り,うまく付き合っていかなければならないことは変わりないところ。
そこで,今回はTwitterAPI2のoauth2.0 に対応しました。TwitterIDとの連携ログインは,ナラベルにとって重要な機能なので,現状のoauth1.0aが非推奨になっても運用上の支障が発生しないようにしておく必要があります。ナラベルはgrailsフレームワークで構築されているので,言語はGroovyです。Javaでの実装も同じステップだと思いますので、参考になればなによりです。
まずは,JavaのSDKの利用環境を設定します。TwitterからAPIv2用のSDKがリリースされましますが,ステイタスはまだβ版です。
build.gradle
implementation group: 'com.squareup.okhttp3', name: 'okhttp', version: '4.11.0'
implementation group: 'org.jetbrains.kotlin', name: 'kotlin-stdlib', version: '1.8.21'
4つのライブラリを読み込みます。
実際の連携ログインの手順としては,
-
- TwitterIDでログインボタンをユーザーがクリック
- Controllerの所定のActionへJump
- Action内でoauth2に必要なオブジェクトの生成と遷移先URLの生成
- Actionから遷移先URLへリダイレクト
- ユーザーが承認
- 前述のActionで設定されたCallBackURLへとリダイレクト
- callbackで指定されたActionで改めてTwitterAPIにアクセスしてユーザー情報取得
- OKであればログイン
となります。ここではoauth2の詳細については,専門ではないので割愛。
で,実装は以下のとおり。
最初に必要なものをimportします。
//*** twitter oauth2
controllerのActionは以下のとおり
//*** twitterLogin :oauth2 ****************************************def twitterLogin2(){
//*** start;log.info("*** twitterLogin2 : LoginController *** ");//*** build callback url;StringBuffer callbackURL = request.getRequestURL();int index = callbackURL.lastIndexOf("/");callbackURL.replace(index, callbackURL.length(), "").append("/twitterCallback2");log.info(" CallBack URL : " + callbackURL.toString());
//*** build oauth2 objecttry{TwitterOAuth20Service service = new TwitterOAuth20Service(callbackURL.toString(), // callback url
String secretState = "state";PKCE pkce = new PKCE();pkce.setCodeChallenge("challenge");pkce.setCodeChallengeMethod(PKCECodeChallengeMethod.PLAIN);pkce.setCodeVerifier("challenge");String authorizationUrl = service.getAuthorizationUrl(pkce, secretState);log.info(" authorization URL : " + authorizationUrl);
//*** save object; callbackで必要なobjectをsessionへ保存def twitteroauth2=[:];twitteroauth2.put("service",service);twitteroauth2.put("pkce",pkce);session.setAttribute("twitteroauth2",twitteroauth2);
//*** redirectresponse.sendRedirect(authorizationUrl);}catch (TwitterException e) {return render(view:'index');}
//*** returnreturn render(view:'index');}
このActionでは、事前にTwitterDevから作成したキーなどを使って、認証先にアクセスするためのリダイレクトURLを生成して、実際にリダイレクトさせています。
次は、認証後のcallback。
//**** twitter callback ******************************************
def twitterCallback2(){
//*** start
log.info("*** twitterCallBack2 : LoginController *** ");
def twitteroauth2 = session.getAttribute("twitteroauth2");
TwitterOAuth20Service service = (TwitterOAuth20Service)twitteroauth2.get("service");
PKCE pkce = twitteroauth2.get("pkce");
session.removeAttribute("twitteroauth2")
//*** null checking
if(!service || !pkce){
return forward(controller:"login",action:"index");
}
//*** get twitter code;
if(!params.code){
log.error(" *** can not get code : callback object : twitterCallBack2 :");
return forward(controller:"login",action:"index");
}
//*** get access token
OAuth2AccessToken accessToken = service.getAccessToken(pkce, params.code);
if(!accessToken){
log.error(" *** can not get AccessToken : callback object : twitterCallBack2 :");
return forward(controller:"login",action:"index");
}
//*** setup apiInstance;
TwitterApi apiInstance = null;
try{
apiInstance = new TwitterApi(new TwitterCredentialsOAuth2(
accessToken.getAccessToken(),accessToken.getRefreshToken()));
}
catch(ApiException e){
log.error(" *** can not build apiInstance : twitterCallBack2 :");
return forward(controller:"login",action:"index");
}
//*** get user info
Set<String> userFields = new HashSet<>(Arrays.asList());
Set<String> expansions = new HashSet<>(Arrays.asList());
Set<String> tweetFields = new HashSet<>(Arrays.asList());
try {
Get2UsersMeResponse result = apiInstance.users().findMyUser()
.userFields(userFields)
.expansions(expansions)
.tweetFields(tweetFields)
.execute();
//** set user Object;
preUser.put("authid",result.data.id);
preUser.put("authnm",result.data.name);
}
catch (ApiException e) {
log.error(e.printStackTrace());
return forward(controller:"login",action:"index");
}
//*** return
return forward(controller:'login',action:'preUser');
流れとしては、oauth1.0aとほとんど変わらないので、差異は使っているAPIの関数やライブラリ。これでAPI1系が非推奨になっても、慌てずに済みそう。当面は、oauth1.0aを利用する予定。
細かい話は、本家のDocを参照してください。
動いてしまえば、そんなに難しくないのですが、いろいろと調べるのに時間がかかってしまったのと、やはりTwitterがどのような対応をしてくるのかの様子見していた関係で、計画から実装までは結構時間がかかってしまいました。コーディング&テストは、実質1日使っていない。
万が一、Twitter連携ログインが完全に停止(もしくは有料化)となった場合には、ユーザーデータの移行も考える必要があるが、そちらの方が悩ましい。
いずれにせよ、Twitter騒動が収まりを見せていることが何よりだ。
図書館員として青春群像劇の小説をタイトルと著者と正しいISBNを表形式で20冊推薦してください
最近はやりのchat-GPTにこの呪文を投げてみた。プロンプトエンジニアの誕生とか言われているが、そういった難しいことはちょっと脇に置いて、直感的に呪文を作った。

選書が微妙な感じではあるが、それっぽく作るのはさすがとしかいいようがない。だが、あくまでもそれっぽくだ。時間のある方は、このリストを検証してほしい。とりあえずは1冊だけ、見てみよう。
| 5 | 『今日も僕は上手に生きている。』 | 紫舟 | 9784864090083 |
特に青春群像劇の小説に詳しい訳ではないので、こんなタイトルもありそうだな、ぐらいの感想だったが、著者の紫舟は、私の知識では書道家であって、小説を書いているかどうかは不明だったので、同姓同名の小説家がいるのかなとも思ったが、そんなはずはないだろうと思い直し… Wikipediaで調べると、やっぱり小説作品はないし、同姓同名の小説家も見つけられない。ISBNは桁数や先頭3桁の国番号は問題ないが、このISBNはAmazonでは何もヒットしない。
さらに言えば、タイトル「今日も僕は上手に生きている」もchat-GPTの創作のようだ。少なくとも、Amazonではヒットしない。
一冊調べただけだが、これではリスト全体として、何が正しくて、何が間違っているか、見当もつかないことになる。
そうは言っても、ここまでそれっぽく作られると、騙される方が悪いと断言できないのではないかと思う。結果検証をしない人なら、chat-GPTがあれば図書館員は不要だと言い出しかねないが、ちゃんと検証すれば、図書館員不要論などは真面目に検証するに値するような話ではないことはすぐに分かる。ただし、現時点ではという条件が付く。未来に何が起きるかは、誰にも分らない。
ついでに、こんなことも聞いてみた。
「図書館員として青春群像劇の小説をタイトルと著者と正しいISBNと要約を付けて5冊推薦してください」
結果は、こんな感じ。

この5冊はすべて未読であるが、唯一、5冊目の「博士の愛した数式」は映画版を見ようとしてあらすじを読んだ記憶があった(映画は見ていない)ので、この要約を読んで、違和感を覚えた。そう、おそらくこの要約もchat-GPTの創作だ。
誤解を恐れずに言えば、ジェネラティブAIは、Web上のさまざまなコンテンツを大量に収集し、それをインプットとして学習して回答を作成する仕組みだ。なので、間違った回答となるのは、学習方法が悪いか、インプットが悪いかのどちらか、もしくは両方と言える。
openAIはchat-GPT3.5から4へと改善版を出してきているし、これからもかなりのスピードで学習方法は改善されていくことは間違いないが、それが事実情報(例えばタイトルとISBNの一致といった事実関係を正確に出力できるか)の取り扱いの改善にどれだけつながるかは未知数だ。しかし、これはジェネラティブAIが本当に役に立つ一般的なツールになるために越えなければならない一つの大きな壁だろう。
学習用のインプットデータとなる情報については、何をしなければいけないのかは現時点では分からない。現在のジェネラティブAIが学習に利用したデータは、そもそもそういった使われ方を想定して作成されているわけではないわけで、当然、機械学習に不向きなデータも多いだろう。今後は、ジェネラティブAIをより実践的なツールとするために、機械学習に使われること前提とした情報発信の仕組みが作り出されるかもしれない。そうなれば、ジェネラティブAIの能力は、さらに向上していくだろうし、図書館はさらなる情報発信によって、自らの存在意義を示すことができるはずである。
図書館は本に関する情報の宝庫だ。ナラベルWebサービスを開発した理由も、図書館や本に関わる人たちが持つ埋もれた有益な情報をWeb上に簡単に公開するためのプラットフォームを作ることだったのだが、これからは一層、情報発信の重要性が増してくる。図書館がジェネラティブAIと全く関係性を築かないという選択肢もあるが、それは図書館自身の存在を社会的に低下させるリスクを内包している。
結局、ジェネラティブAIと本に関わる人々は共存共栄関係を作り上げていくことになるのではないだろうか。巷では、ジェネラティブAIの拡大によってなくなる仕事の話が面白おかしく取り上げられているが、そんな簡単なことではない。
ちなみに、同じ質問をBingAIで聞いた結果は、こんな感じ

参考情報サイトが示されているので、情報の信頼度を検証することも可能だろうが、これがどこまで有効なのか、まだまだ分からない。ちなみに、やはりいろいろ正しくないことばかり。
図書館の代打役としてchat-GPTを少し使ってみたが、図書館サービスとしての活用のツボが見つけられていない。しかし、PG用のスニペット作成ツールとしてはかなり便利だ。うまく使えば、開発コストを下げられる。
技術革新への対応は、抗うよりも、上手に関係性を築いていくことが大切なのだろう。ゼロサムゲームで済むことは、リアルな世界ではほとんどない。いずれにしろ、何かに最適化しながら生き続けていくことになると思うが、本と図書館が何に対してどのように最適化していくのか、そしてナラベルWebサービスがどのように役立っていけるのか、開発・運用者としてはワクワクすることも多い、というのが正直な気持ちである。
ナラベルWebサービス2.0 リリース!
ナラベルWebサービス2.0が2023年1月29日にリリースとなりました。ご協力いただいたみなさま、そしてチームメンバーに感謝申し上げます。
ナラベル2.0は、1.0バージョンとメイン機能は共通するものの、サービスコンセプトを大幅に変更し、本棚サービスとして運用開始となりました。
キャッチフレーズは、
”インターネット上に本棚をつくろう!”
です。
本棚サービスですから、なんと言っても特徴は、本棚です。

本棚に並ぶ本は、1つの本棚だけではなく、いろいろな本棚にナラベらています。1冊の本が、別の本棚へとユーザーを誘う、それがナラベル2.0の魅力。そこにはきっと、予期せぬ一冊との出会いが待っているはず。
書店や図書館で本棚を眺めながら本との出会いを探したように、インターネット上の本棚で、本との出会いを探してもらえたら、そんな思いが、ナラベル2.0につながっています。
もし、あなたが誰かに知って欲しい本があるなら、ナラベルを使って、本棚にナラベてください。誰かが作った本棚たちと思わぬ一冊でつながって、誰かの生活を豊かにするかもしれません。
皆さんと一緒に、ナラベルを育てていければ、スタッフ一同にとって、何もの代えがたい喜びです。
小さなチームの小さなシステムですが、どうぞよろしくお願いいたします。
【追記】
ナラベル2.0には、新たにマスコットが誕生しています。

ベルルは、ナラベル2.0に在住です。時々、本棚をつくります。

ナーラは、ナラベルのPR担当です。Twitter上で活動しています。今後、ナラベル2.0にも登場予定です。
ナラベルマスコットも、ぜひ御贔屓に。

いいね!機能の実装
ナラベルWebサービスにいいね!機能が実装されました。
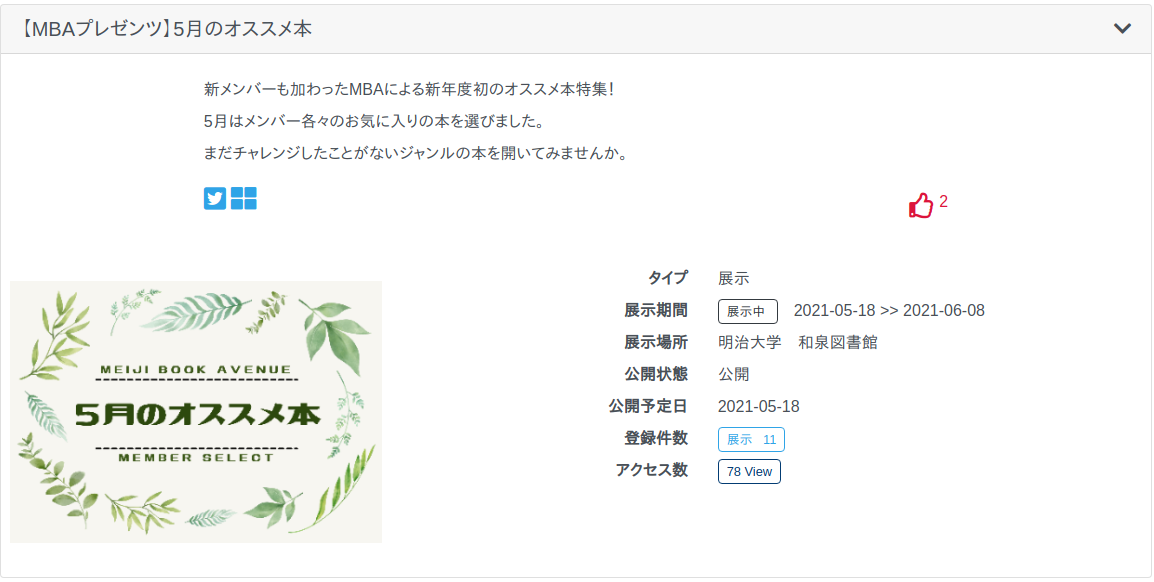
右端に赤色のいいね!ボタンが表示されるようになりました。ここをクリックすると,いいねの回数が1つ増えます。もう一度クリックすると,取り消しとなります。
いいね!ボタンを押すのに,ログインなどの必要はありません。誰でもクリックしていただけます。
システムの仕様の関係で,いいね!の回数は,一覧ページへの反映は,適時となりますので,クリックした直後に一覧ページに戻っても,いいね!の回数が増えていないことがありますが,最長でも翌日には反映されます。
この仕様は,次期開発には解消する予定です。
ユーザーのエントリーが役に立ったときには,ぜひいいね!ボタンをクリックしてください。